



日本地震频发,却关心中国光刻机是否突破瓶颈,中国芯片能否乘机站上风口
作者:包可萌
就在日本频繁地震,东京有明显震感,全球光刻胶供应稳定性扑朔迷离的时刻,市场传闻日本将在12月中旬对华断供光刻胶产品,随后日本媒体《日经亚洲》连发数篇文章称,中国将成为全球第三个可以独立制造光刻机的国家。
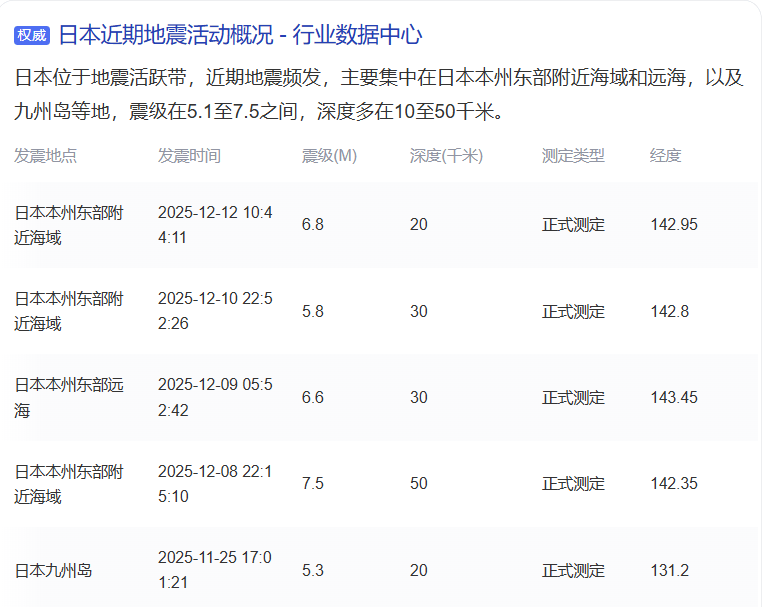
回溯中国光刻机发展历史,曾经也是全球第一梯队。在上世纪70年代末,中国光刻机展开接触式、接近式光刻机及投影式光刻技术研究,80年代末就实现第一台分步式光刻机的开发,但多种因素影响下,90年代至本世纪初,中国光刻机研发显著落后。
凭借半导体发源地优势,美系厂商在光刻机竞争中率先起步,日系企业依托精密光学与政策扶持在DUV时代登顶,中国为应对全球竞争,不得不先采购美日生产的光刻机,至2024年,中国已成为全球最大光刻机采购市场,贡献ASML营收41%,外界普遍猜测,这是中国在美彻底封锁光刻机出口前集中采购。
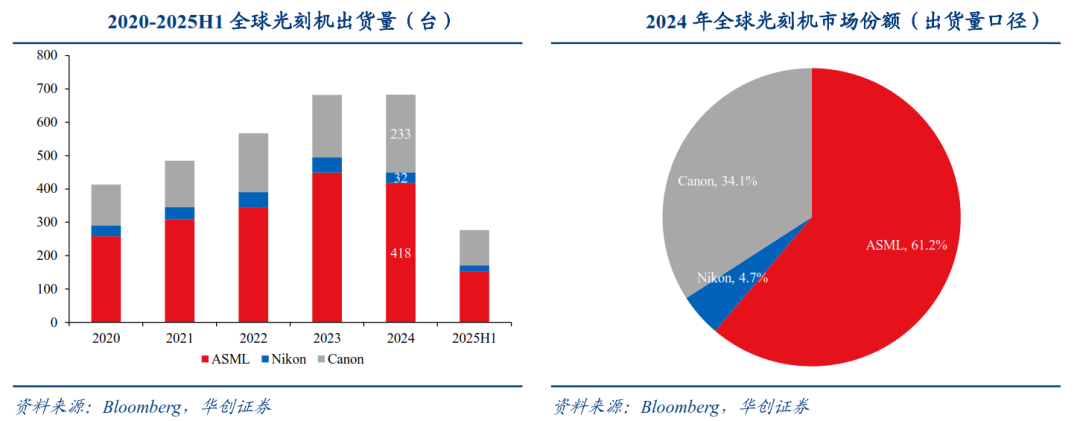
从2018年开始,美国施压对华高端光刻机的出口,之后又陆续出台“1007新规”等针对政策,限制对中国出口先进制程芯片设备,包括EUV光刻机和先进型号的DUV光刻机,联合日本荷兰制定相关出口条例共同对华进行产业封锁,中国自此加速光刻机国产替代进程,至2025年,中国在光刻机领域已经取得明显突破。
在此期间,美国鼓动其盟友限制向中国出口光刻机,导致中国多种芯片短缺的窘迫局面已经大幅改善,华为麒麟旗舰芯片已于2023年重新投产并应用于其旗舰手机,如今就连特朗普政府严格限制出口,中国人工智能行业亟需的高端GPU也被传将恢复出口。
只可惜国内厂商已经对英伟达祛魅,比如科大讯飞就已经使用基于国产算力打造自主可控通用大模型底座,英伟达已经彻底失去中国高端GPU市场,黄仁勋在纽约出席Citadel Securities活动时坦言,受美国出口限制影响,公司在中国高端AI芯片市场的份额已从过去的95%归零。
近期英伟达又被爆出使用芯片定位技术,用以遏制其GPU被滥用于受限国家和地区及被限制企业,联想到俄保时捷遭锁死断电事件,国内算力需求大厂们使用国产GPU可谓是顺理成章。

简单梳理不难发现,中国芯片业的突围,始于国产光刻机取得重大突破。
01 国产光刻机元年
网传2025年是中国国产光刻机爆发式增长元年,公开资料显示,上海微电子自主研发的600系列光刻机已实现90nm工艺的量产,并正在进行28nm浸没式光刻机的研发工作。
另据2024年发布的《首台(套)重大技术装备推广应用指导目录(2024年版)》,国产氟化氩(ArF)光刻机的核心指标为光源波长193纳米、分辨率≤65纳米、套刻精度≤8纳米,这标志着国产ArF光刻机在成熟制程(如55-65nm)芯片制造上具备了应用基础。

单纯看工业应用,实现55nm工艺制程的国产化替代,就已经足以应对涉及安全等战略层面的芯片应用,进一步研发28nm及以下先进工艺光刻机,是为了保证高性能计算、旗舰手机、先进AI算力芯片等核心领域的硬件安全。
2025年9月15日,2025年国家网络安全宣传周网络安全企业家座谈会在昆明召开,座谈会上明确了头部企业需扛起“卡脖子”技术攻关责任,聚焦芯片等关键领域,联合高校院所打造创新联合体,加速研发自主可控安全芯片以突破垄断。
面对外部封锁压力,在国家政策支持下,国内企业加速研发突破光刻机制造技术,宇量昇与中芯国际的合作测试是国产光刻机突破的重要信号。
据公开资料显示,宇量昇成立于2022年7月,为国有控股企业,定位“半导体专用设备研发与制造”,聚焦EUV光刻机国产化,目标构建独立于美国的半导体设备生态。
光刻机技术的突破将带动上游材料、精密机械等配套产业升级,加速光刻胶、光学部件等“卡脖子”材料的国产化进程,形成“龙头带动、多点突破”的产业升级格局。
相信在多方努力下,国产光刻机将陆续攻克核心技术节点,国产光刻机产业链,已经实现从成熟制程向先进制程加速跃迁,行业发展重点也由“补短板”向“建体系”转变,以多重曝光、自对准图形化、先进对准系统为代表的关键工艺能力不断增强,使得中国在14nm甚至7nm可实现路径上具备了自主探索的可能。
02 高端工艺制程国产化遇阻背后的“弯道超车”
提及国产7nm工艺,绕不开华为2023年发布的麒麟9000系芯片。此时正是美国禁止所有使用美国技术的晶元代工厂替华为加工芯片的关键时期,因此市场普遍认为麒麟9000是中国厂商代工。
市场首先想到的代工厂就是中芯国际,因为中芯是内地制程工艺最先进的晶元代工厂,也是目前除台积电外,全球唯一一家明确表示将持续研发7nm及更先进工艺制程的晶元代工厂。
早在2020年,中芯国际对标7nm工艺的N+1先进工艺芯片完成流片和测试,与14nm相比,N+1工艺在性能方面提升20%、功耗降低57%、逻辑面积缩小63%、SoC面积减少50%,至2025年,有公开消息称,中芯国际14nm良率大于95%,7nm量产稳步推进。
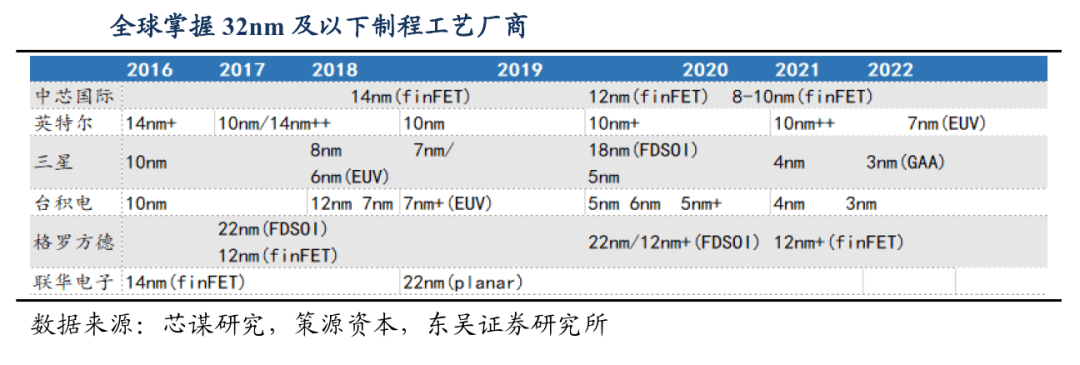
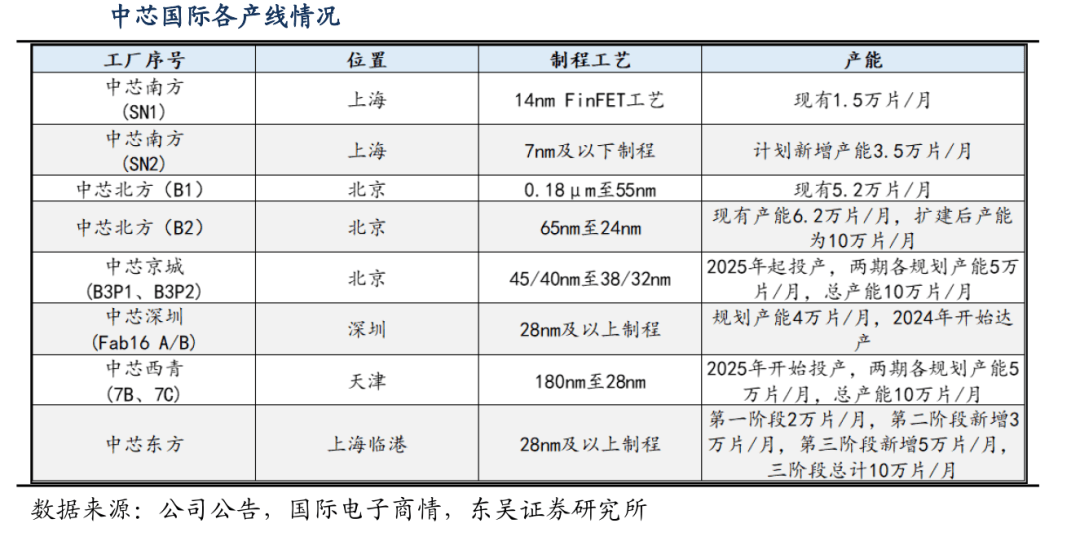
如今伴随华为昇腾、寒武纪、摩尔线程、沐曦股份等为代表的国产算力提供商逐步走向台前,市场对上述芯片企业的代工厂充满好奇,但从公开资料来看,并未有厂商明确表示晶元代工厂,多数人只从企业公开的GPU参数上,猜测能满足这个工艺标准的晶元代工厂是中芯,针对华为芯片的代工厂,除中芯代工外,还有传闻称华为自有工厂加工。

以华为昇腾910C为例,该产品用7nm+EUV工艺,将FP16算力推至448TFLOPS,并较910B功耗再降15%;而且910C采用Chiplet双芯封装,1024芯片集群FP16算力达819.2PFLOPS,可对标NVIDIA H100集群,支撑千亿参数模型训练。
华为 CloudMatrix384单机柜集成384颗昇腾910与192颗鲲鹏CPU,FP16峰值300PFLOPS,跨节点延迟<1µs,线性扩展度95%,在DeepSeek-R1预填充效率4.45tokens/s/TFLOPS,优于SGLang在NVIDIA H100默认配置下的3.18tokens/s/TFLOPS;验证国产超节点已具备规模化商用能力。

另一家国产GPU大厂寒武纪,旗下思元590支持8芯片级联,FP16集群算力2.048PFLOPS,通过动态稀疏计算提升30%效率,性能达到英伟达A100集群的70%。
华为CANN、海光DTK、寒武纪BANG+MagicMind等自研软件栈同步落地;商汤DeepLink跨10余款国产芯片完成千亿参数模型20天不间断训练,效率保持95%
在华为带动下,国产芯片份额持续提升。IDC数据显示,2024年中国加速芯片市场规模超270万张,其中国产人工智能芯片出货量超82万张,占比超30%;央视新闻预计2025年昇腾芯片出货量将超70万片。
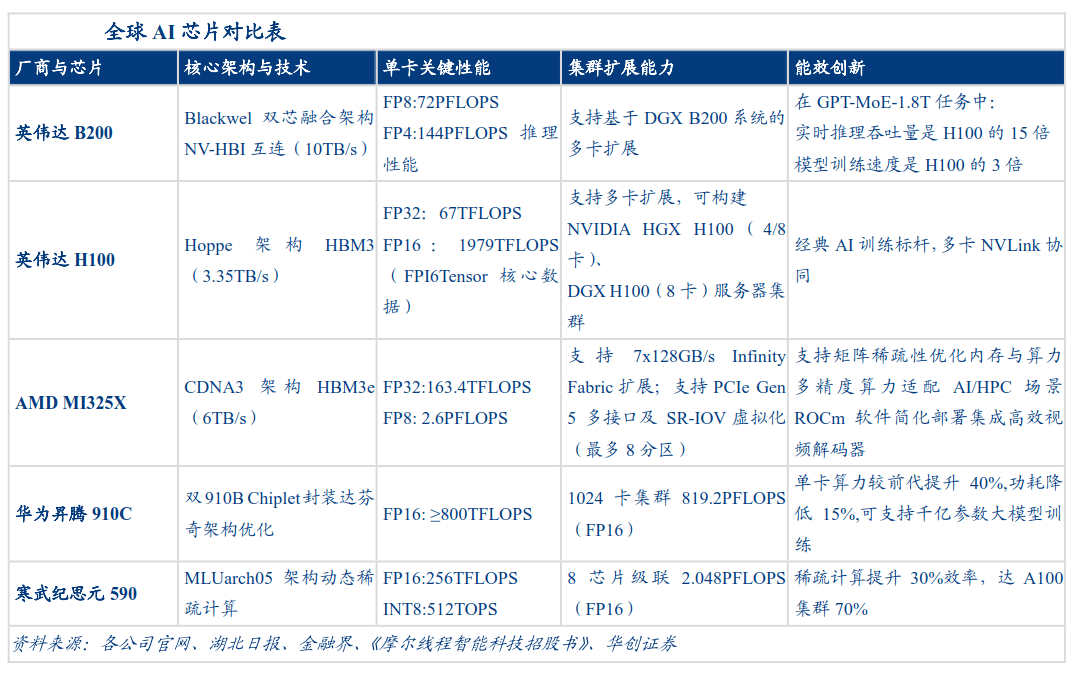
细分到数据中心GPU市场,2024年上半年英伟达虽以80%份额领先,但国产阵营突破明显:华为以17%份额位列第二,百度、寒武纪等合计占3%。从增长动能看,华为同比增速达287.0%,寒武纪等厂商亦表现亮眼,国产芯片替代活力持续释放。
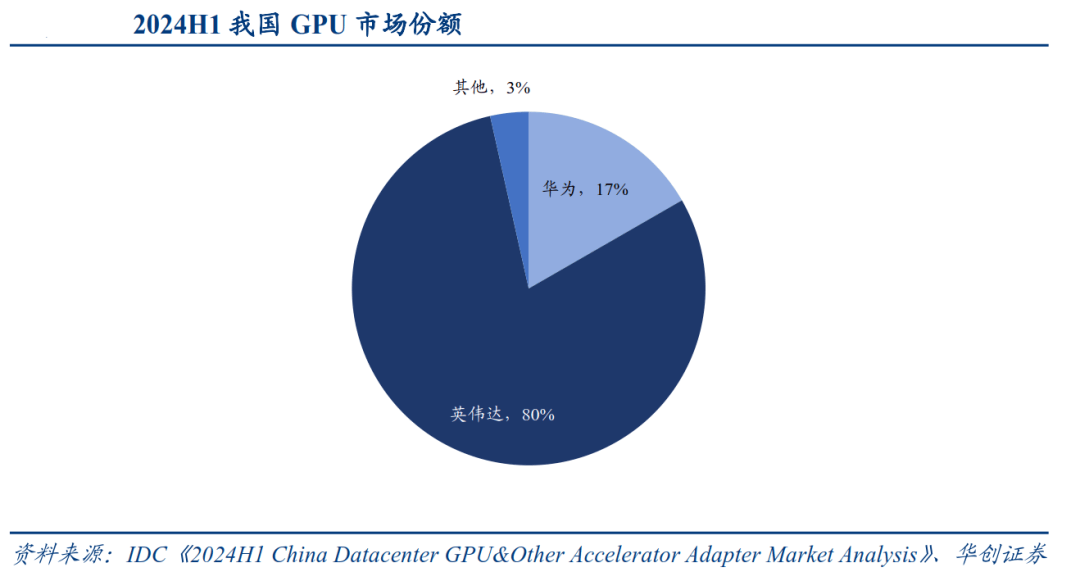
03 多维技术路线并行
在全球芯片先进制程竞争日趋激烈背景下,国际巨头持续突破物理极限,而国内在 7nm 及以下先进制造环节虽仍存在瓶颈,以华为为代表的国内企业,试图在成熟先进工艺与架构创新上实现弯道超车。
华为昇腾910通过32核达芬奇架构设计实现256TFLOPS的半精度算力,运算密度超越同期NVIDIA TeslaV100;中芯N+1代工艺助力芯片功耗及稳定性上与7nm工艺相似,加之华为等设计企业与本土制造环节的深度协同,国内正逐步缩小与国际先进水平的代差,为突破先进制造瓶颈奠定基础。
具体来看,华为Atlas系列推理卡、视频解析卡等产品覆盖多样场景需求;寒武纪思元系列板卡(如MLU370-S4/S8等)在计算精度、视频编解码等能力上不断突破;摩尔线程S5000、MTTS80等产品亦在AI计算加速、图形渲染赛道发力。
尽管上述产品与英伟达高端产品仍存在差距,但国内GPU单卡性能提升路径清晰,正通过架构创新(如昇腾达芬奇架构、寒武纪MLUarch03架构)与技术整合(先进Chiplet、MLU-Link多芯互联等)逐步缩小代差。
在此过程中,国内厂商在国产化替代与新兴场景拓展中持续构建自身竞争优势,推动GPU生态向多元化方向发展。
以摩尔线程为例,作为2024年以来科创板最大规模IPO,摩尔线程已成功量产五颗芯片,迭代四代 GPU 架构和智能SoC产品,实现从芯片、计算卡到智算集群的多元布局,形成了覆盖人工智能、科学计算与图形渲染等完整的计算加速产品矩阵,全面支持“云-边-端”全场景。摩尔线程已成为国内少数能够提供从FP8到FP64全计算精度支持的GPU厂商之一,也是国内率先推出支持DirectX12图形加速引擎的国产GPU企业。
沐曦股份科创板IPO申请于2025年6月30日获得受理,12月5日完成申购,即将成为摩尔线程后第二家登陆A股的国产GPU公司。该公司旨在打造全栈 GPU 芯片产品,推出曦思®N 系列 GPU 产品用于智算推理,曦云®C 系列 GPU 产品用于通用计算,以及曦彩®G 系列 GPU 产品用于图形渲染,满足“高能效”和“高通用性”的算力需求。
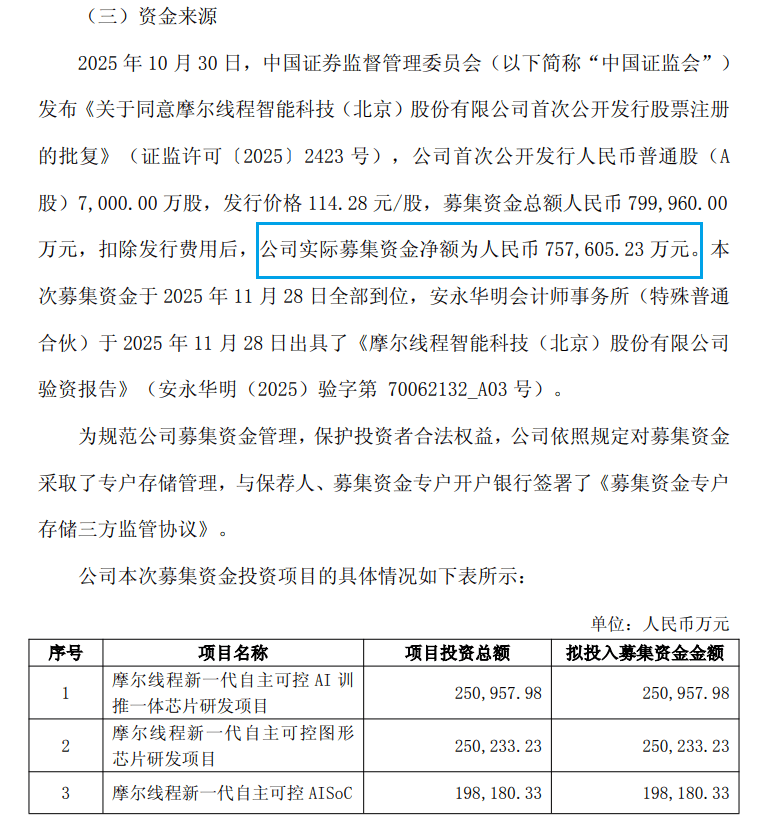
只是在摩尔线程登陆科创板仅6个交易日后,摩尔线程就发公告称使用75亿元闲置募集资金进行现金管理,值得注意的是,摩尔线程实际募集资金净额也不过75.76亿元。

此举引发网友激烈讨论,关于摩尔线程股价后续表现,只能拭目以待12月15日开盘的表现。

04 结语
且不论摩尔线程“使用部分闲置募集资金进行现金管理”这一举措优劣,在全球半导体技术竞争重新洗牌的关键节点,国产芯片设计厂无疑会搭上芯片设备国产替代的东风,实现企业自身技术、市场地位进一步提升。
当外部封锁将产业链推向前所未有的深水区,国产设备却在压力之下迸发出惊人的系统性进化:从成熟制程的全面补齐,到浸没式 DUV 的整机突破,再到 EUV 原型技术的加速登场,中国正在构建一条独立于既有体系之外的“第二光刻技术路径”。
这不仅是一场设备能力的跃迁,更是一场围绕材料、光学、精密制造、算法与工艺的国家级创新协同。
过去十年,中国光刻机只是“能用”;未来十年,它将决定中国半导体能否真正跨过产业分水岭,重塑全球先进制造的力量格局——而这一场景正从实验室、从关键样机、从一系列不起眼但关键的突破中被快速推向现实。
© THE END
素材皆来自官方公开资料
本文不构成任何投资建议。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






